ML Lecture 3 Part I Model Training Basics
ML 模型训练中的基础概念
监督学习流程 Supervised Learning Flow
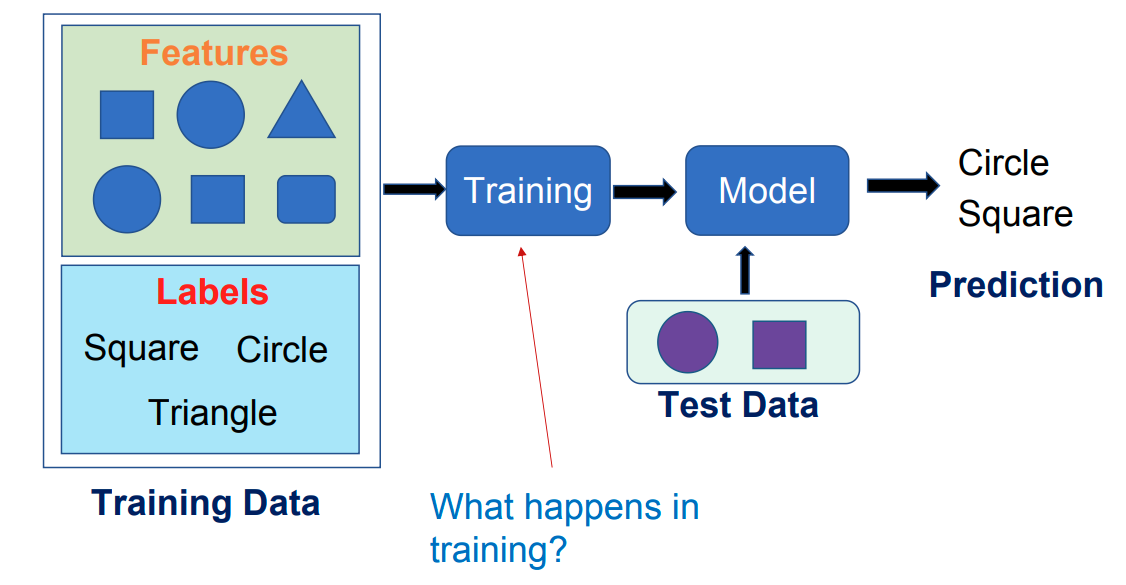
超参数与模型参数 Hyperparamters vs. Model Parameters
模型参数是模型内部的配置变量,它们的取值由数据来估计得到。
模型参数是在训练过程中学习得到的。 例如:线性回归中的系数 www 和常数项 bbb。
超参数是预先设定的参数,它们的取值用来控制学习过程。
超参数是由人工在训练开始之前设定的。 例如:KNN 中的 kkk 等。
损失函数 Loss Function
损失函数是用来评估真实值(标签)与模型预测值之间差异的函数。 由损失函数计算得到的数值称为“损失”(loss)。
损失函数有多种形式:
- Mean squared error
均方误差(MSE) - Mean absolute error
平均绝对误差(MAE) - Categorical cross entropy
分类交叉熵 - ...
模型训练 Model Training
模型训练的目的,是寻找一组最优的模型参数 Parameter,使损失最小。
训练一个模型的步骤:
- Step 1: 首先,定义一个损失函数。
- Step 2: 然后,最小化这个损失函数。
- Step 3: 从而获得最优的模型参数。
Train a model ⟺ Minimize a function
回归中的损失函数:Mean Squared Error (MSE)
其中
- MSE 对预测值是凸 Convex 且可导 Differentiable的;在线性回归中,它对模型参数也是凸函数,因此便于优化。
- MSE 对离群点 outliers 不鲁棒 robust。
离群点:与其他数据点明显不同的数据点。 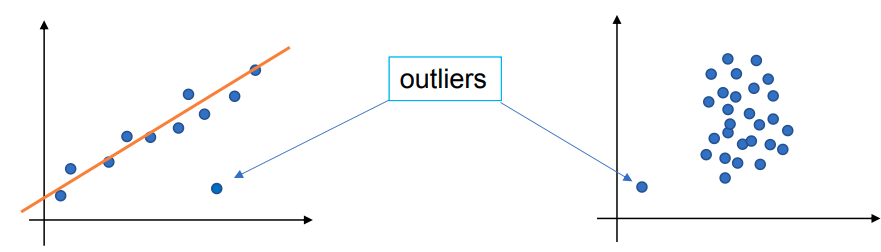
- 如果第
个样本是离群点,那么 - 由于在 MSE 中该差值
回归中的损失函数:Mean Absolute Error (MAE)
- MAE 对离群点更加鲁棒。
- 但是它不可导,因此优化起来比较困难。
MSE 会放大(平方级)大误差的影响。为了最小化总损失,模型会被迫“用力”去迁就这个离群点,导致模型参数发生剧烈偏移,从而牺牲了对正常点的预测准确度。而 MAE 只是线性地看待这个错误,不会因为它是离群点就给予过度关注。
从统计学角度来说,最小化平方误差会得到条件均值估计,最小化绝对误差会得到条件中位数估计。中位数受到个别离群点的干扰明显小于均值。
分类中的损失函数
二元交叉熵 Binary Cross Entropy
二元交叉熵通常使用在分类数为2的情况。
其中
多类交叉熵 Categorical Cross Entropy
对于多类别分类问题,使用多类交叉熵。
其中
- 交叉熵对预测概率是可导的(在概率不为 0 或 1 的区域内),因此更易于配合梯度法优化。
- 交叉熵本身关于预测概率是凸的;在神经网络等非线性模型中,整体目标函数对模型参数通常是非凸的,可能具有多个局部极小值 Local Minima。
线性回归模型的训练
在线性回归中,损失函数通常用 MSE 来定义:
为真实值;
最小化损失
我们的目标是最小化损失,也就是求解下面这个无约束优化问题:
其中
连续可导且凸。 - 梯度下降 Gradient Descent Algorithm 适合用于最小化这个损失。
最小化损失函数:梯度下降 The Gradient Descent Method
梯度下降是一个一阶的迭代优化算法,用来寻找可微函数的局部最小值。 梯度下降迭代 Gradient Descent Iteration:
其中
其中
梯度下降算法步骤:
- 将
设置为任意初始点; - 按照式
例如:使用梯度下降算法最小化: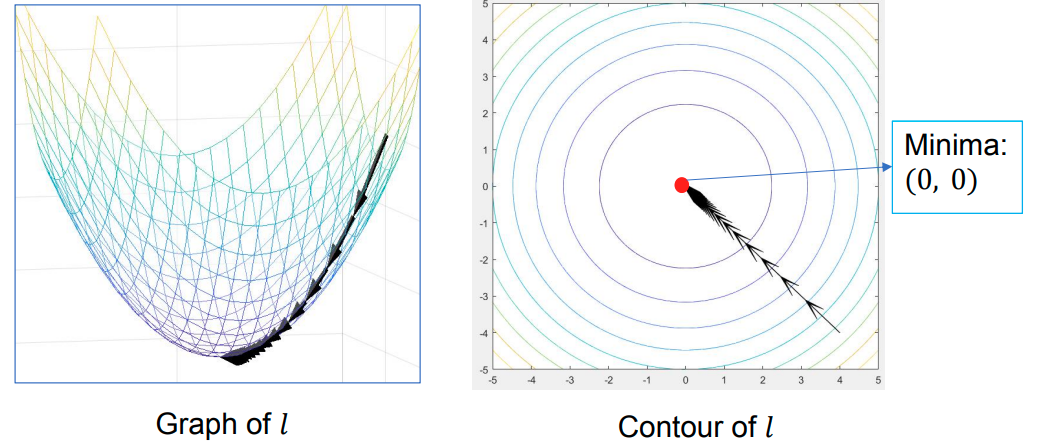
批量梯度下降 Batch Gradient Descent (BGD)
对于一个线性回归,其损失函数可写为:
计算梯度:
批量梯度下降(BGD)每次使用全部
个训练样本来计算梯度; 然后使用平均梯度来更新模型参数(例如线性回归中的
和 )。 优点:在合适条件下收敛性有保证。
缺点:探索能力较弱、内存消耗较大。
随机梯度下降 Stochastic Gradient Descent (SGD)
- 从训练集中取出一个样本;
- 计算该样本对应的梯度;
- 按照梯度更新模型;
- 对训练集中的所有样本重复步骤 1-4。
优点:
- 需要的内存更少。
- 探索能力更强。
缺点:
- 模型更新频繁,计算开销大;
- 梯度噪声较大,收敛速度可能较慢。
小批量梯度下降 Mini-batch Gradient Descent (MBGD)
- 在 BGD 中,每次使用全部样本。
- 在 SGD 中,每次只使用一个样本。
- 在 MBGD 中,每次使用一个**小批量 Mini-batch。
一个小批量包含
- 把数据集划分为若干个小批量;
- 从训练集中取出一个小批量;
- 计算该小批量样本的平均梯度;
- 根据平均梯度更新模型;
- 对所有小批量重复步骤 2–4。
在 MBGD 中,
较小时,行为类似于 SGD; 较大时,行为类似于 BGD。
一个常用的默认Batch Size是 32。
MBGD 是 BGD 和 SGD 的一个结合,故
- 在一定程度上可以避免收敛到不好的局部最小点;
- 所需内存较少;
- 收敛速度较快。
ML 模型评估中的基础概念
训练数据与测试数据 Training & Test Data
在机器学习中,数据集通常被划分为训练集和测试集。 训练集用于训练机器学习模型,而测试集用于作为基准来评估一个已训练好的模型。 我们使用 预测误差Prediction Error 来评价模型:
prediction error = Bias² + Variance + Noise
即 预测误差 = 偏差² + 方差 + 噪声。
噪声 Noise
- 噪声是模型也无法消除的误差 error,是不可约 irreducible的。
偏差 Bias
- 偏差是模型平均预测值与我们想要预测的真实值之间的差异。
- 它既来源于模型本身的假设,也来源于训练过程。
方差 Variance
- 方差是针对同一个数据点,模型预测结果的变化程度 Variability。
- 它与训练过程密切相关。
欠拟合 Underfitting
偏差较大的模型,会在训练集和测试集上都产生较大的误差。 高偏差模型可能由于:
- 对训练数据做出了过于强烈的假设;
- 欠拟合 Underfitting。
欠拟合指的是:模型既不能很好地拟合训练数据,也不能很好地泛化到新的数据。Underfitting refers to a model that can neither model the training data well nor generalize to new data.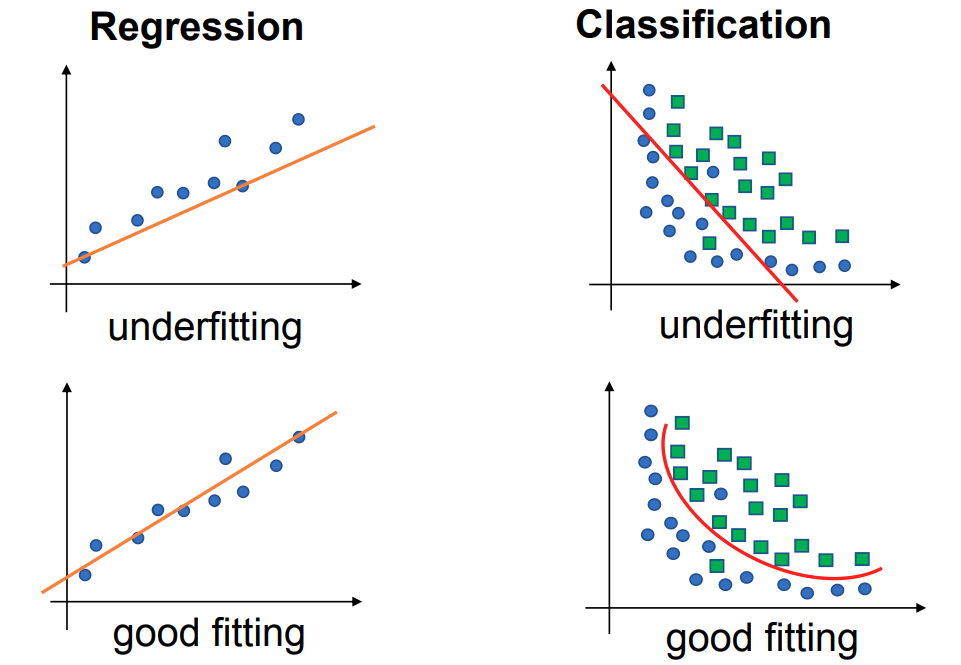 检测欠拟合 欠拟合通常比较明显,因为它在训练集和测试集上的表现都不好。
检测欠拟合 欠拟合通常比较明显,因为它在训练集和测试集上的表现都不好。
避免欠拟合的方法:
- 换用其他机器学习算法;
- 延长训练时间(多训练一些轮次)。
过拟合 Overfitting
方差描述的是:当使用不同的训练数据集时,目标函数估计值改变的程度。 方差较高的模型,会在测试数据上产生较大的误差。 高方差往往意味着算法把训练数据中的随机噪声也当成了模式来学习,即发生了过拟合 Overfitting。
过拟合是指模型对训练数据“拟合得太好”,甚至把噪声也当成了有用的模式来学习。 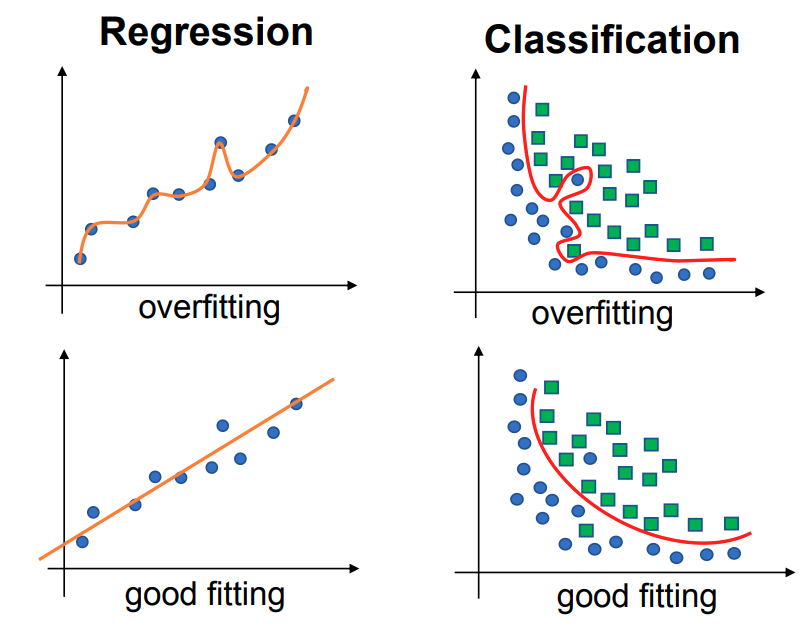 检测过拟合 如果模型在训练集上的预测误差远远小于在测试集上的误差,就很可能已经过拟合。
检测过拟合 如果模型在训练集上的预测误差远远小于在测试集上的误差,就很可能已经过拟合。
避免过拟合的方法:
- 增加训练数据量;
- 移除与任务无关的特征;
- 使用早停 Early Stopping(在验证集上性能不再提升时停止训练)。
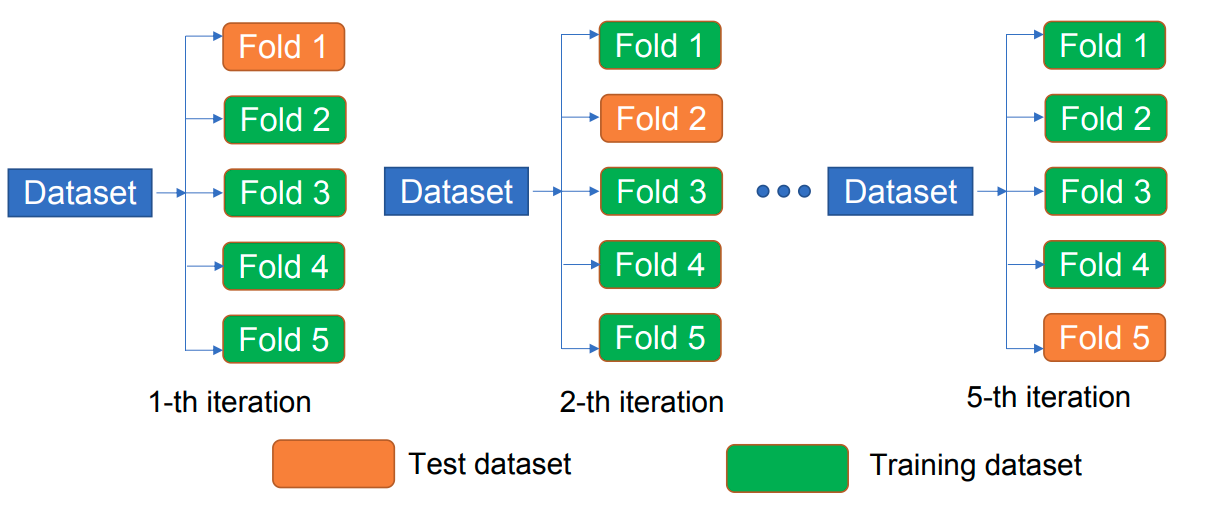
通过
在完成
。 评估结果的波动可以通过这些误差的标准差估计:
。 基于误差的均值和波动,我们就可以对模型做出较客观的判断,也可以在此基础上调节超参数、比较不同的机器学习模型。这里的标准差反映交叉验证分数的稳定性,不等同于偏差-方差分解中的 Variance。
偏差-方差权衡 Bias-Variance Trade-off
偏差与方差之间存在此消彼长的关系:
- 增大偏差通常会减小方差;
- 增大方差通常会减小偏差。
所以,需要在偏差和方差之间取得一个好的平衡,从而使总误差最小。 最佳情况下既不过拟合也不过欠拟合。 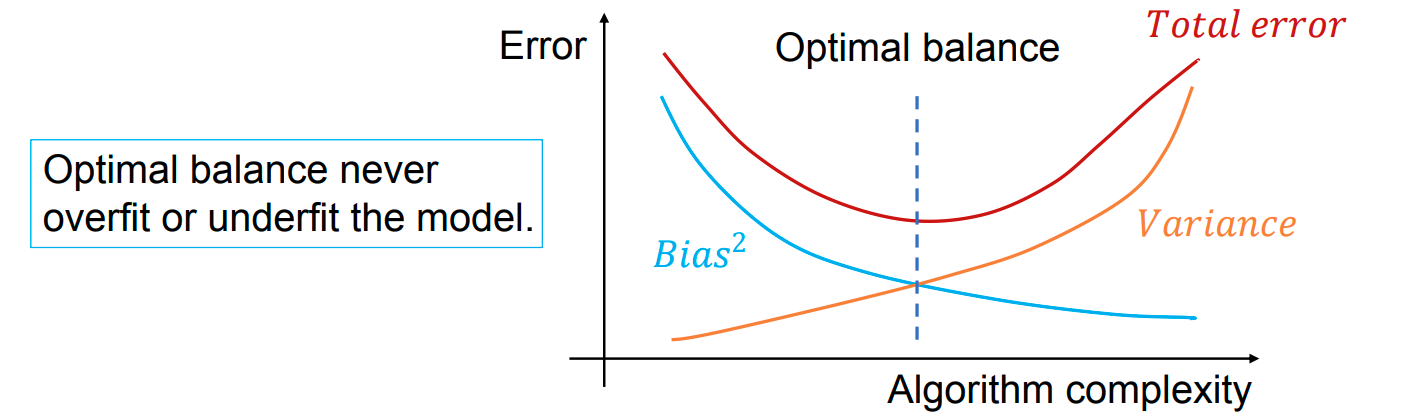
泛化 Generalization
泛化指的是:机器学习模型从训练数据中学到的知识,在未见过的新数据上表现得有多好。
一个好的机器学习模型,应该能够把从训练数据中学到的模式很好地泛化到该问题域中的其他数据上。